
Read the paper - DOI: https://doi.org/10.1093/jamia/ocad100
Premise
Machine learning models are not widely being used at the bedside of hospitals. One potential reason is optimism, defined as the difference between models' performance on retrospective data versus actual performance when used in real-life scenarios. Models that have high optimism (i.e., perform well on retrospective data but poorly at the hospital bedside) can lead to non-use of these models. We trained machine learning models for two different tasks—ICU mortality (predicting whether a patient will survive their ICU stay) and Bi-Level Positive Airway Pressure failure (predicting if a patient will fail their BIPAP intubation). These models were developed using different data partitioning methods, and optimism was measured for each method.
This paper was featured on Journal of the American Medical Informatics Association's (JAMIA) website and won editor's choice.
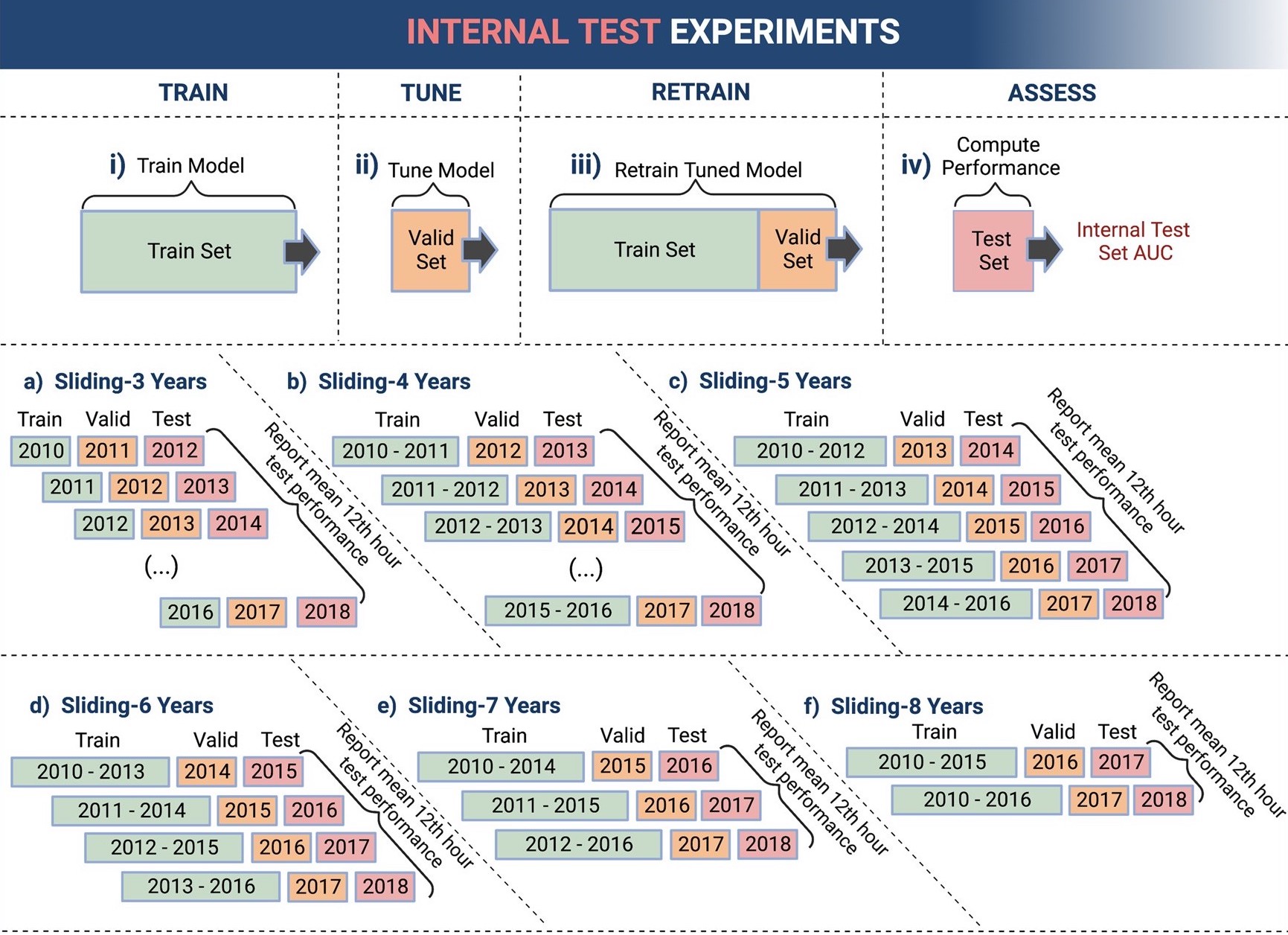
Data partioning methods
I coded, visualized, and assessed all the data partioning methods, i.e. different ways to assess how a model will perform when it is deployed. The language, tools, and primary packages I used were Python, Jupyter Notebook, Pandas, Scikit Learn, Matplotlib, and Plotly. Between the two tasks of predicting mortality and BIPAP failure, there were ten total data partioning methods and one hundred forty trained machine learning models.
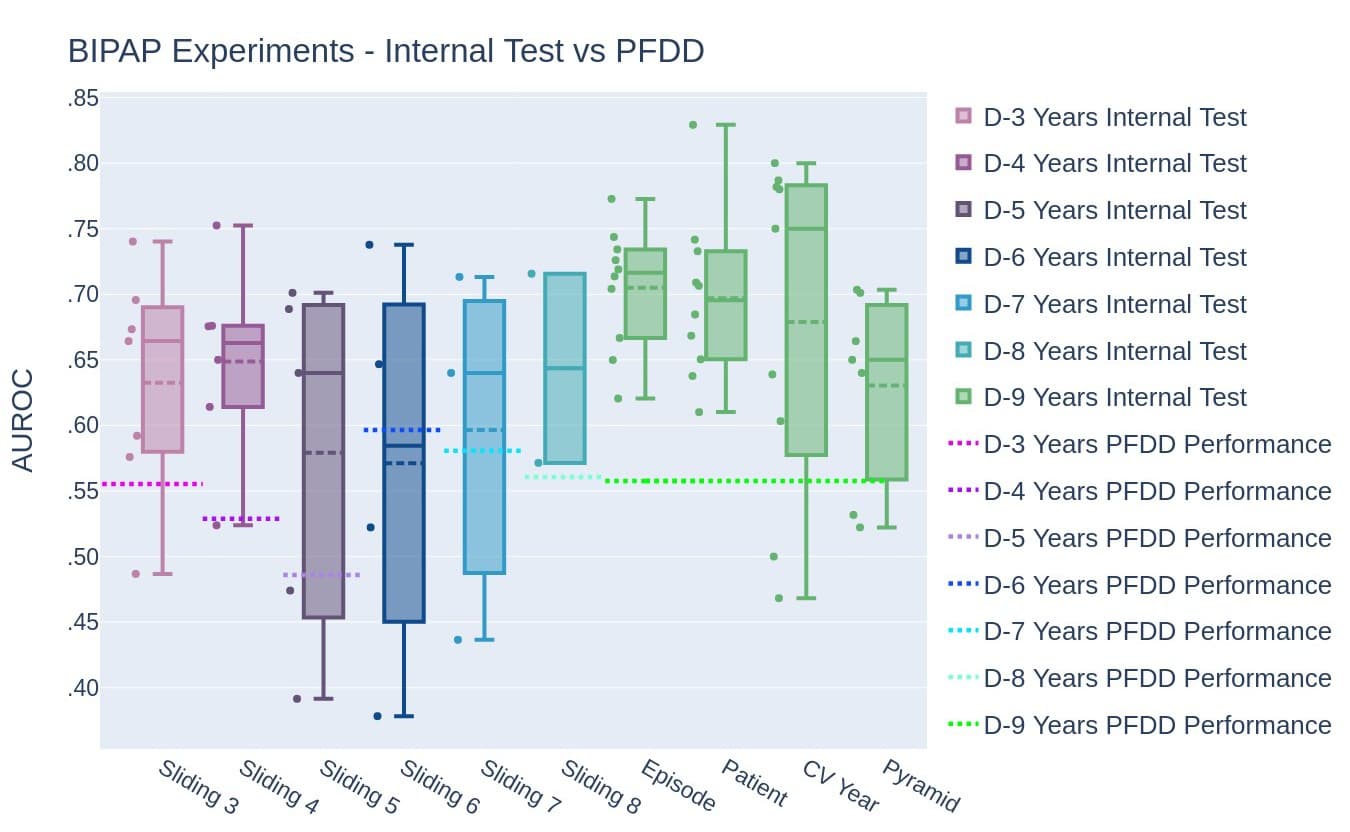
Conclusion
The best data partioning method was proper longitudinal ordering between development and test sets, which mimics real-life scenarios where data from the future is simply not available. Developing machine learning models that best mimic real-life scenarios leads to low optimism.